
Anonymiserat produktionsdata - Myt eller ren fiktion: del 3
Del 3: Anonymiserat eller syntetiskt testdata
Nu har jag skrivit om testdata och problem kring GDPR och anonymisering, nu kommer jag till den enligt mig mest intressanta och relevanta frågan: är anonymiserat produktionsdata ens önskvärt?
För att det ska vara önskvärt måste det för det första täcka mitt behov av testdata, men helst ska det vara effektivt att använda också. Jag tänker visa hur produktionsdata i de flesta fall misslyckas kapitalt på bägge områdena.

Som konsult möter jag i princip dagligen kunder som har problem med testdata och kunder som vill få i gång testautomatisering, men som inte lyckas. I de flesta fallen handlar det om att kunden vill använda produktionsdata som testdata, ibland med anonymisering för att säkerställa att man följer GDPR.
Med den här artikeln vill jag slå hål på myter kring att produktionsdata är lämpligt testdata och att personuppgifter blir lagligt testdata om man bara anonymiserar. Artikeln är indelad i 5 avsnitt enligt bilden och det här är den tredje avsnittet som fokuserar på om produktionsdata överhuvudtaget är önskvärt som testdata.
Anonymiserat eller syntetiskt data
Dom flesta av oss är idag vana vid att arbeta agilt, att planera ett 6 månaders projekt är ett minne blott och vi har accepterat fördelarna med att kunna anpassa oss efter behovet. Själva grundprincipen i agila arbetssätt är att vi aldrig vet så lite om behovet som i börja av ett projekt, och därför ses kraven i början av utvecklingen mer som riktlinjer och så uppdaterar vi kraven allteftersom vi förstår behovet bättre. Men ändå envisas vi med att skapa testdata just i börja av projektet, just då som vi egentligen inte förstår vad som ska testas och vilket data vi behöver, och då blir det lätt att använda produktionsdata som ”rimligen” täcker behovet (som man inte riktigt har definierat ännu).
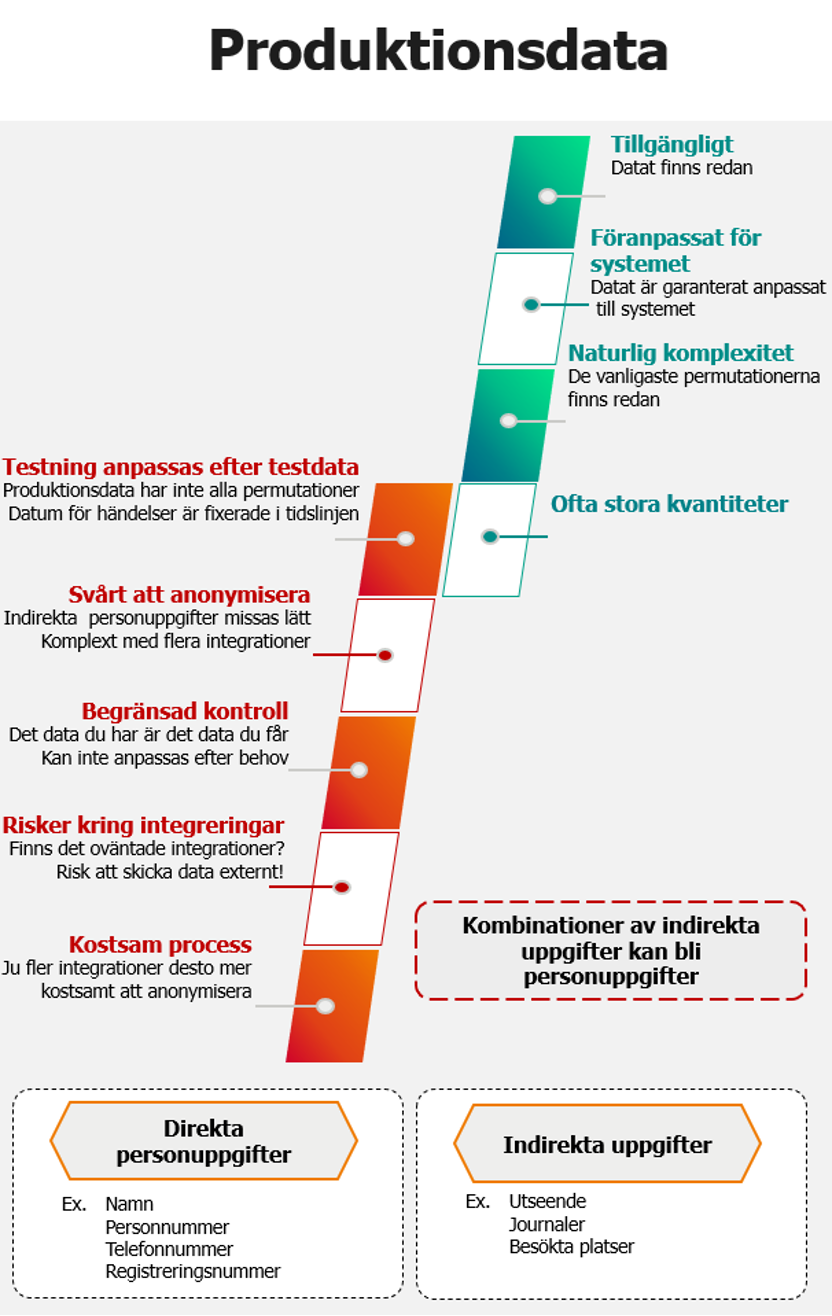
Produktionsdata
Produktionsdatat har inbyggda fördelar som exempelvis att det är lätt tillgängligt, det fungerar garanterat i systemet, det täcker de flesta variationerna och det finns massor av det. Just det att de flesta variationer finns med redan från början är lockande för många eftersom det innebär att man inte måste förstå sig på komplexiteten av sitt systemdata redan från början.
Men produktionsdata är också begränsande. Med produktionsdata får vi det vi har, men inte nödvändigtvis det vi behöver. Kvantitet över kvalitet. Vi förlorar också alla anspråk på kontroll och i regel måste vi anpassa testningen efter existerande data.
Hitta relevant data
I mängden av produktionsdata kan det kan vara svårt att hitta rätt data och ofta slösas mycket tid på att identifiera det data som behövs, och när man väl testat en gång är just detta data ofta förbrukat. Om vi exempelvis söker någon som fyller 18 år just idag, så lär hen inte göra det igen i morgon, eller i övermorgon.
Då måste vi börja om inför nästa testomgång, och om vi skriven en felrapport blir det problematiskt att beskriva hur felet kan reproduceras när aktuellt testdata redan är förbrukat.
Tidsaspekt och händelser
Det produktionsdata vi kopierar idag blir gärna inaktuellt i framtiden, då måste vi ladda om nytt data och anonymisera på nytt. Den här processen i sig, kan i komplexa system ta en vecka eller mer och stör så klart både utveckling och test. I ett projekt jag var involverad ville man använda produktionsdata för utveckling och test eftersom man ansåg det omöjligt att syntetiskt reproducera de 70 000 existerande accessgrupperna. I sak är det korrekt, men i praktiken var ingen intresserad av att testa alla 70 000 grupper, faktum är att över 90% var inaktuella redan vid start, problemet var att ingen visste vilka. I slutändan verifierades bara en handfull grupper och de hade kunnat skapas syntetiskt så hade vi sluppit förseningar p.g.a. anonymisering och omladdning av data 2 gånger.
Vissa händelser är mindre förutsägbara än en 18 års dag, ett ITSM system måste exempelvis kunna hantera otrevligheter som dödsfall. Om vi förlitar oss på anonymiserat produktionsdata och externa integrationer för händelser riskerar vi att få vänta länge på de dåliga nyheterna, dessutom misstänker jag att motivationen kommer att sjunka drastiskt. Om vi inför intern kontroll över själva händelsen vinner vi mycket, men med en så känslig händelse ökar så klart risken och därmed kraven på anonymisering och att isolera testmiljön.
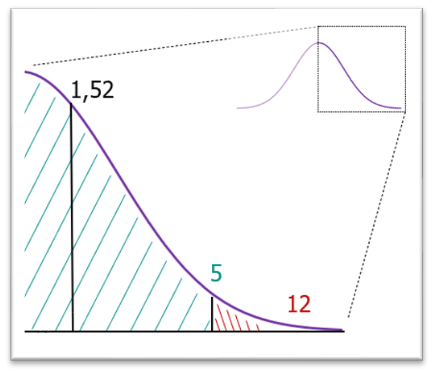
Outliers
Så kallade outliers saknas ofta i produktionsdata. Bilden bredvid visar en fiktiv normalfördelningskurva över antal barn per kvinna. Här hittar vi familjer med 0-3 barn i parti och minut just för att bulken av vårt data centreras runt snittet på 1,52. En typisk outlier skulle vara att hitta en familj med exempelvis 12 eller 17 barn och det blir svårare. Paradoxalt är det rent testmässigt just outliers, eller gränsvärden som är mest intressant.
Anpassning till ny funktionalitet
Produktionsdatat är till sin natur anpassat efter existerande funktionalitet, men inte nödvändigtvis relevant för nyutvecklad funktionalitet. Med produktionsdata blir är det en ekvation som inte ofta inte går att lösa, man behöver data för utveckling och test, men man behöver funktionalitet för att skapa data. Ett klassiskt moment 22.
Kvantitet
Ett vanligt argument för produktionsdata är kvantitet. Kvantitet behövs i första hand vid stabilitetstest, ofta för att verifiera att bakgrundprocesser klarar av att hantera realistiska kvantiteten. Det används även för att verifiera KPI (Key Performance Index), exempelvis att tjänster levererar resultat inom relevanta tidsramar. Men med produktionsdata kan vi som mest matcha dagens kvantiteter, medan med syntetiskt data har vi inga direkta gränser. Vi kan matcha förväntade kvantiteter för i morgon, nästa år eller nästa årtionde.
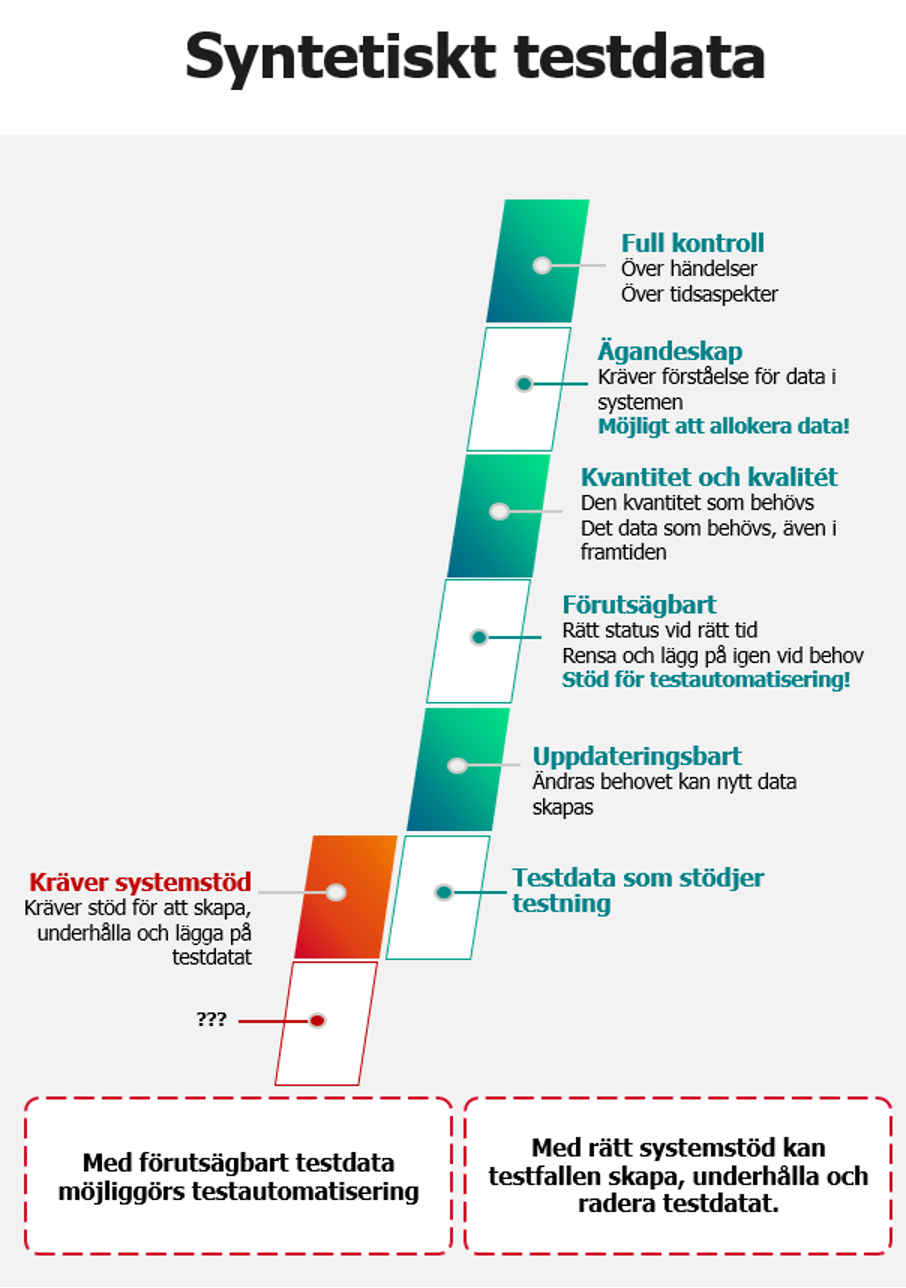
Syntetiskt data
Syntetiskt data kräver mer resurser i början, man behöver tänka till och planera och ofta behövs någon form av systemstöd för att skapa, dokumentera och underhålla testdata på ett effektivt sätt. I gengäld får man relevant data, kontroll, förutsägbarhet och oftast bättre möjlighet att allokera testdatat (möjliggör för olika testteam att utföra sitt arbete utan att störa varandra), men framför allt får man möjlighet att dynamiskt skapa och uppdatera testdata efterbehov.
Med syntetiskt data behöver alltså testdata inte vara en statisk kvantitet skapad som förberedelse inför ett projekt och vi behöver inte heller söka efter rätt data. I stället kan vi bokstavligt talat börja med noll och dynamiskt bygga relevant testdata varefter behovet uppstår. Om behovet ändras kan vi uppdatera vårt testdata. På så sätt kan vi över tid täcka samtliga permutationer, variationer, gränsvärden och outliers.
Om varje projekt dynamiskt skapar sitt eget testdata, skapas också en naturlig separation som kan användas för allokering, därmed kan risken att projekten att störa varandra genom att använda samma testdata minimeras eller till och med elimineras.
Kort sagt, med syntetiskt data och rätt processer skapar vi ägandeskap, kontroll och förutsägbarhet. Det här är exakt vad som behövs för testautomatisering, men mer om det i ett senare avsnitt.
Sammanfattning
Produktionsdata löser bara problemet med att definiera testdatat innan vi förstått behovet fullt ut, det inger en falsk trygghet att oavsett vad som händer så har vi i alla fall testdata som fungerar. Men sanningen är att det ofta är bristfälligt, statiskt, och har dåliga förutsättningar att täcka ny funktionalitet.
Med syntetiskt data möjliggör vi ett agilt arbetssätt där vi dynamiskt skapar det data vi behöver vartefter behovet uppstår. Vi kan arbeta enligt devisen ”börja litet och väx” och med tiden kommer det nästan alltid att betala sig både ekonomiskt och kvalitetsmässigt.

Inläggsförfattare
Terminologi och referenser
[1] GDPR General Data Protection Regulation
På svenska: Dataskyddsförordningen (DSF)
[4] Syntetisering
Att skapa data som inte har någon koppling till verkligt data och därmed inte kan härledas till någon individ eller organisation
[6] Verifikation
I testsammanhang definieras test som att leta efter fel eller potentiella fel. Verifikation däremot förutsätter att test redan utförts och syftar till att verifiera att funktionaliteten som tidigare testats inte har försämrats. Ett typexempel är att testa funktionaliteten, men efter att ett nytt uppgraderingsförfarande använts, verifierar man att funktionaliteten fortfarande är intakt för att säkerställa att processen fungerat.
[7] Mitigera
Att mildra eller lindra skärpan eller intensiteten av något.
Se Svenska akademins ordbok (www.saob.se)



