
Anonymiserat produktionsdata - Myt eller ren fiktion: del 2
Anonymiseringsprocess
Jag tillhör den lilla lyckligt lottade gruppen av människor som faktiskt tycker om testdata, dels för att det är utmanande att försöka representera en slags verklighet, men framför allt för att jag tycker om att effektivisera processer. I min tidigare blogpost skrev jag om GDPR och testdata, den här gången fokuserar jag på anonymiseringsprocessen och de problem som gärna uppstår, vanligtvis sent i processen när man redan investerat åtskilligt med tid och det kan vara svårt att backa.

Som konsult möter jag i princip dagligen kunder som har problem med testdata och kunder som vill få i gång testautomatisering, men som inte lyckas. I de flesta fallen handlar det om att kunden vill använda produktionsdata som testdata, ibland med anonymisering för att säkerställa att man följer GDPR.
Med den här artikeln vill jag slå hål på myter kring att produktionsdata är lämpligt testdata och att personuppgifter blir lagligt testdata om man bara anonymiserar. Artikeln är indelad i 5 avsnitt enligt bilden och det här är den andra delen som handlar om risker kring anonymisering av produktionsdata.
Anonymiseringsprocess
Det är idag mycket vanligt att man vill använda produktionsdata som testdata och att man påbörjar en anonymiseringsprocess. På det sättet slipper man oroa sig för GDPR och man kommer i gång fort, men det finns några fallgropar som är värda att nämnas.
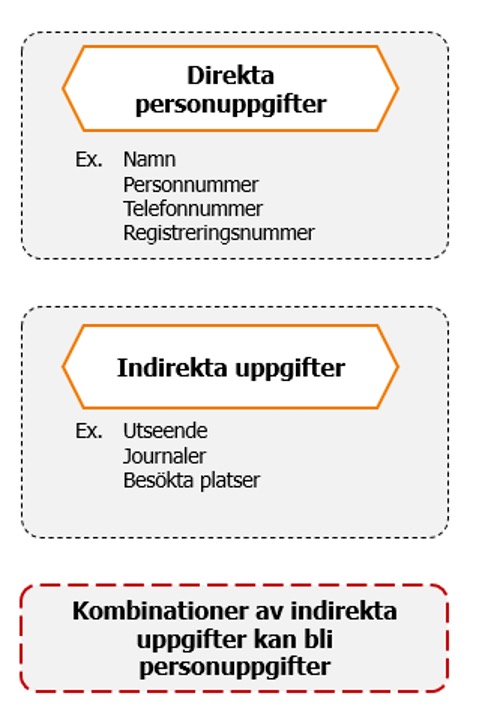
Indirekta personuppgifter
Att maskera direkta personuppgifter, så som personnummer eller namn, kan vara svårt i sig, men det är i det närmsta trivialt i förhållande till indirekta personuppgifter.
Indirekta personuppgifter är all information som indirekt pekar ut individen. En registreringsskylt kan användas för att identifiera ägaren, till och med en bild på en bil utan registreringsskylt kan vara personuppgifter om bilen i sig är unik. Ett annat bra exempel är när uppgifter som inte är personuppgifter i sig kan bli personuppgifter när de kombineras, exempelvis om man spar uppgifter om var och när en företagsbil parkerat. Flera parkeringar på samma dag kan göra att kollegor eller kunder kan identifiera vem det är som kört, dessutom kan parkeringen i sig vara en extra skyddsvärd uppgift om man till exempel åker till en läkarmottagning eller behandling. Ett annat exempel är journaler, att diagnostiseras med förkylning är i sig ingen personuppgift eftersom man knappast är ensam om det, men om man i Sverige diagnosterseras med malaria så är diagnosen mer unik och kan då vara en personuppgift. Eller om man har flera diagnoser som tillsammans utgör en unik kombination.
Vi tar ett exempel och försöker oss på att anonymisera en databas för journaler i sjukvården. Vi förutsätter att alla namn och personnummer redan är anonymiserade. Eftersom vi är medvetna om indirekt personuppgifter anonymiserar vi även diagnos, biverkning och medicin. Vår patient har nu fått diagnosen ”Himpavimpa” med biverkning i from av ”Högfärdshosta” och ska nu få recept för ”Silversked-i-munnen”. För att kunna lägga in dessa val i journalen måste de först finnas i en drop-downlista, så innan vi kan journalföra måste vi anonymisera alla kartlagda diagnoser, biverkningar och mediciner, utan att tappa koppling till övriga patienter!
Det mest motsägelsefulla här är att det är ofta just dessa uppgifter som ligger till grund för att vi vill använda produktionsdatat. Komplexiteten i from av patienters sjukdomshistoria, diagnoser, biverkningar, remisser och recept är så klart mycket komplex och det är svårt att förutspå exakt vad som kommer att behövas.
Fiktiva ID
När vi anonymiserar ID räcker det inte med att vi hittar på ett nytt ID, inte ens en perfekt randomiseringsprocess kan garantera att ID’t inte matchar ett riktigt ID. Om det matchar ett riktigt ID har vi inte anonymiserat, vi har bytt identitet. Det här gäller så klart även pseudonymiserat eller syntetiserat testdata.
Ett alternativ är att använda Skatteverkets lista på fiktiva ID, men det är relativt begränsat. Det absolut bästa är om man slå av valideringar av personnumret och använder personnummer som inte fungerar med Luhn-agoritmen[5]. Ett annat bra alternativ är att använda personnummer med datum som är orealistiska (ex månad 13, eller den 40e i månaden), då kan Luhn-algoritmen fortfarande användas för validering.
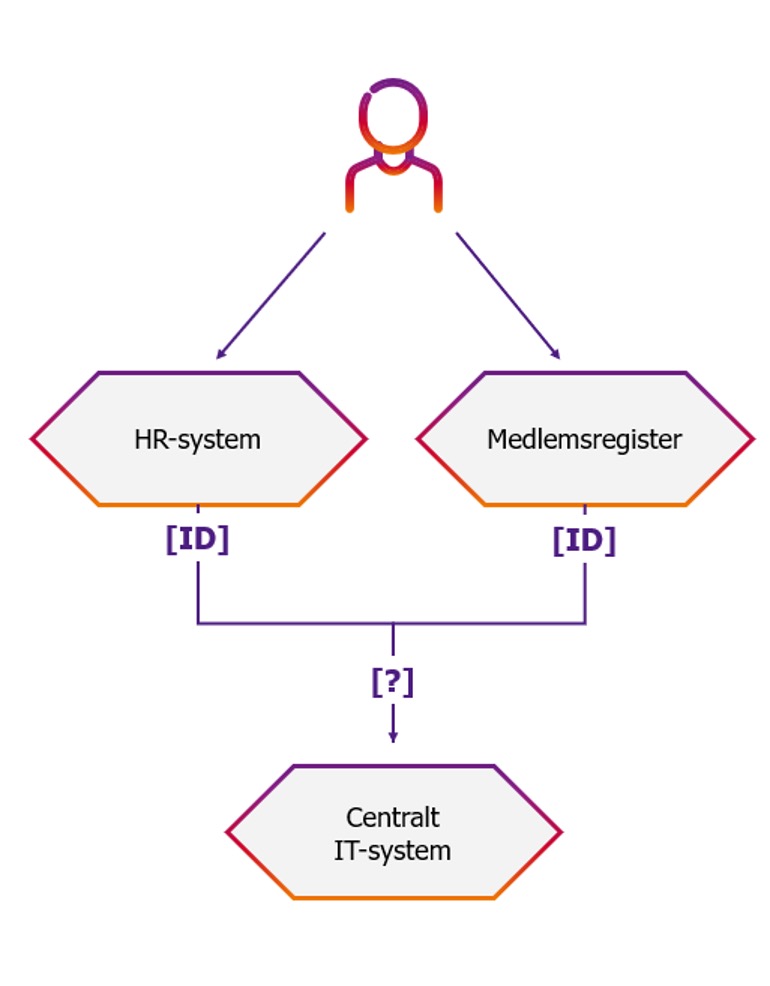
Synkronisering
När vi anonymiserar data kan vi även stöta på synkroniseringsproblem. Tänk exempelvis på ett museum där man har ett HR system för anställda och ett medlemsregister för medlemmar. Om en anställd också är medlem måste personens ID anonymiseras likadant i bägge systemen, annars blir det lätt problem nedströms när dessa inte matchar. De här blir ofta extra problematiskt när man integrerar mot externa system där man inte har kontroll över anonymiseringsprocessen och problemet accentueras ytterligare när man integrerar mot fler externa system som rimligen inte använder samma anonymiseringsprocess.
Sammanfattning
Det i särklass vanligaste skälet till att man vill använda produktionsdata som testdata är att det innehåller en naturlig komplexitet, det vill säga det täcker de flesta fall som man vill testa. Det gör att man kan använda data utan att först behöva fråga sig vilket data man faktiskt behöver. Ironiskt nog gör anonymiseringsprocessen att integrationsproblemen vanligen ökar när komplexiteten ökar, det vill säga: Ju större behovet är av att använda anonymiserat produktionsdata, ju svårare blir det.
Terminologi och referenser
[1] GDPR
General Data Protection Regulation
På svenska: Dataskyddsförordningen (DSF)
[2] Anonymisering
Att ändra på information så att den inte går att härleda till en enskild individ. En envägsprocess, det vill säga att det inte går att vända processen för att identifiera individen
[3] Pseudonymisering
Att ändra på information så att den oinvigde inte kan härleda till en enskild individ. Den som besitter rätt information kan vända processen och identifiera individen. Syftet är att informationen ska vara anonym för det flertal som bearbetar informationen men inte behöver veta vem det berör, men att utvalda individer ska kunna identifiera individen vid behov
[4] Syntetisering
Att skapa data som inte har någon koppling till verkligt data och därmed inte kan härledas till någon individ eller organisation
[5] Luhn-algoritm
En matematisk algoritm som används för att validera rimlighet av exempelvis personnummer eller kontonummer. I exempelvis personnummer är den sista siffran beräknad med Luhn-algoritm och benämns kontrollsiffra. Algoritmen är inte till för att bekräfta att personnumret är korrekt, det syftar bara till att upptäcka de mest uppenbara felskrivningarna
[6] Verifikation
I testsammanhang definieras test som att leta efter fel eller potentiella fel. Verifikation däremot förutsätter att test redan utförts och syftar till att verifiera att funktionaliteten som tidigare testats inte har försämrats. Ett typexempel är att testa funktionaliteten, men efter att ett nytt uppgraderingsförfarande använts, verifierar man att funktionaliteten fortfarande är intakt för att säkerställa att processen fungerat.
[7] Mitigera
Att mildra eller lindra skärpan eller intensiteten av något. Se Svenska akademins ordbok (www.saob.se)

Inläggsförfattare



