
Anonymiserat produktionsdata - Myt eller ren fiktion: del 5
Del 5: Testautomatisering
Testningens heliga gral, men bara om det fungerar friktionsfritt. Jag har stött på fall där testautomatisering verkligen effektiviserat testprocessen och hjälpt till att öka kvalitén, men i allt för många fall går man bara ifrån ineffektiv manuell testning till lika ineffektiv automatiserad testning. Så vad avgör om automatiseringen blir bra? Det finns så klart många skäl, men i grunden har jag funnit ett par grundorsaker som jag vill gå igenom här.

Som konsult möter jag i princip dagligen kunder som har problem med testdata och kunder som vill få i gång testautomatisering, men som inte lyckas. I de flesta fallen handlar det om att kunden vill använda produktionsdata som testdata, ibland med anonymisering för att säkerställa att man följer GDPR.
Med den här artikeln vill jag slå hål på myter kring att produktionsdata är lämpligt testdata och att personuppgifter blir lagligt testdata om man bara anonymiserar. Artikeln är indelad i 5 avsnitt enligt bilden och det här är den sista delen, som handlar om testautomatisering.

Ofta grundar sig problemen i att man inte har en strategi för när och varför man exekverar testfallen, de exekveras flera gånger om dagen mest för att de kan exekveras. I andra fall handlar problematiken om att utfallet inte är deterministiskt, det testdata man är beroende av ändras utan förvarning, eller miljön är inte tillräckligt stabil för att för att exekvera testfallen med positivt resultat.
I grund och botten är det de tre faktorer vi ser i bilden bredvid vi måste fokusera på för att möjliggöra automatiserad testning: Strategi, miljö och testdata
Miljö har jag redan behandlat i avsnitt 4, så nöjer mig med att referera dit och säga att vi behöver kontroll över händelser i testmiljön och att jag starkt rekommenderar en isolerad testmiljö.
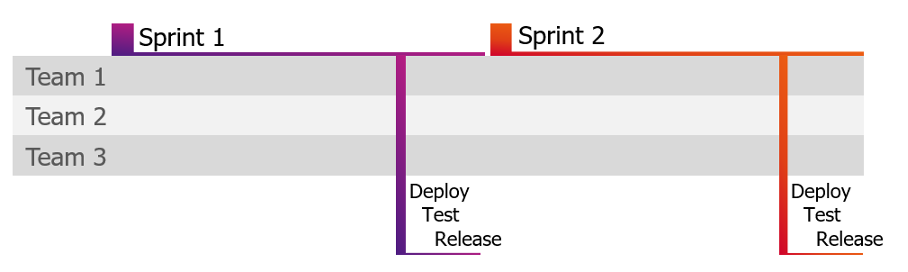
För att effektivt kunna automatisera testning behövs en strategi, och helst en bolagsöverskridande strategi som synkroniserar exekveringen så att alla vet när detta sker och därför inte stör ut varandra. En strategi som ligger nära till hands är att alltid exekvera direkt efter uppdatering för att verifiera att legacy-funktionalitet fortfarande är intakt. Använder man sig av CI/CD kan man med fördel deploya i en mellanmiljö där exempelvis automatiska regressionstester, säkerhetstester och användbarhetstester körs, om testerna går igenom deployas mjukvaran vidare till en gemensam testmiljö. Man kan också exekvera precis innan en uppdatering för att säkerställa att systemet är i gott skick, många har felsökt problem som man trott varit relaterade till en uppgradering, men som visar sig varit aktiva redan innan uppgraderingen.
Testautomatisering är bara effektivt om man ska exekvera testerna många gånger, men det betyder också att vi måste underhålla testerna över tid. Regressionstester är ett bra exempel som ofta exekveras efter varje uppgradering. Att skapa automatiska tester är i sig utveckling och bör behandlas som utveckling med versionshantering, planerat underhåll och överenskommen praxis för designval. Exempelvis kan man vid testning av webapplikationer använda Page Object Pattern (POP) som separerar variabel- och konfigurationsvärden per websida. Resultatet är att om något ändras på en sida kan du justera värden in en fil och det slår igenom på samtliga testfall relaterat till den websidan.
Strategi
Jag har stött på flera fall där automatiska tester exekveras utan strategi, ingen vet riktigt vad syftet är eller när de ska exekveras. Resultatet är oftast att man exekverar vid mer eller mindre slumpmässiga tillfällen och att flertal testfall misslyckas på grund av omständigheter man inte har kontroll över, det kan vara andra system som är mitt i en uppgradering, testdata som är inaktuellt eller testfall som in inte uppdaterats. Över tid brukar det resultera i att man inte vågar lita på resultaten och till sist rinner allt ut i sanden.
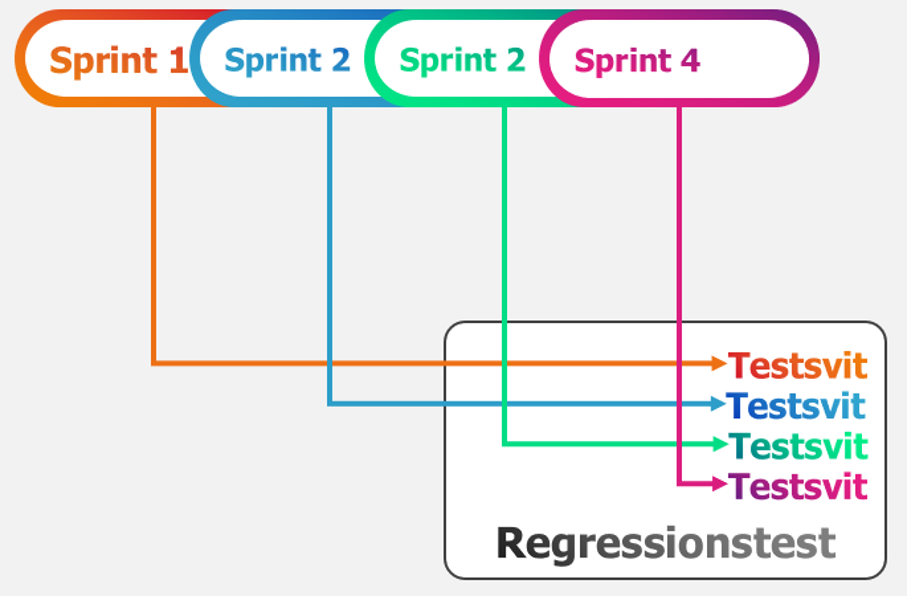
Testfall kan med fördel utvecklas parallellt med ny funktionalitet och allra bäst fungerar det tillsammans med testdriven utveckling. Om en utvecklare först kodar funktionalitet och sedan skapar testfall, går dom lätt in i testningen med för mycket kunskap om funktionaliteten för att opartiskt kunna testa. Testningen blir då lätt en slags självuppfyllande profetia. Om utvecklare i ställer först skapar testfall baserat på hur man ska verifiera att kraven uppfyllts och därefter utvecklar funktionaliteten kommer man runt detta problem och ofta blir kodningen också effektivare. När funktionaliteten är kodad och klar kan testfallen exekveras och vid leverans av nya funktionaliteten flyttas testfallen över till regressionstestsviten, se bilden bredvid.
Eftersom testningen i sig ofta påverkar testdatat kan det vara en bra idé att låta testfallen återställa datat. Om vi exempelvis testar access för en användare kan vi vi verifiera att användaren inte har access, öka accessen och verifiera att användaren har access och till sist återställa accessen. Därmed är testdatat redo för nästa exekvering.

Testdata
För att testdata ska stödja testautomatisering måste vi ha kontroll över testdatat och för att få det måste vi hantera två aspekter, testdatat måste var förutsägbart och dynamiskt.
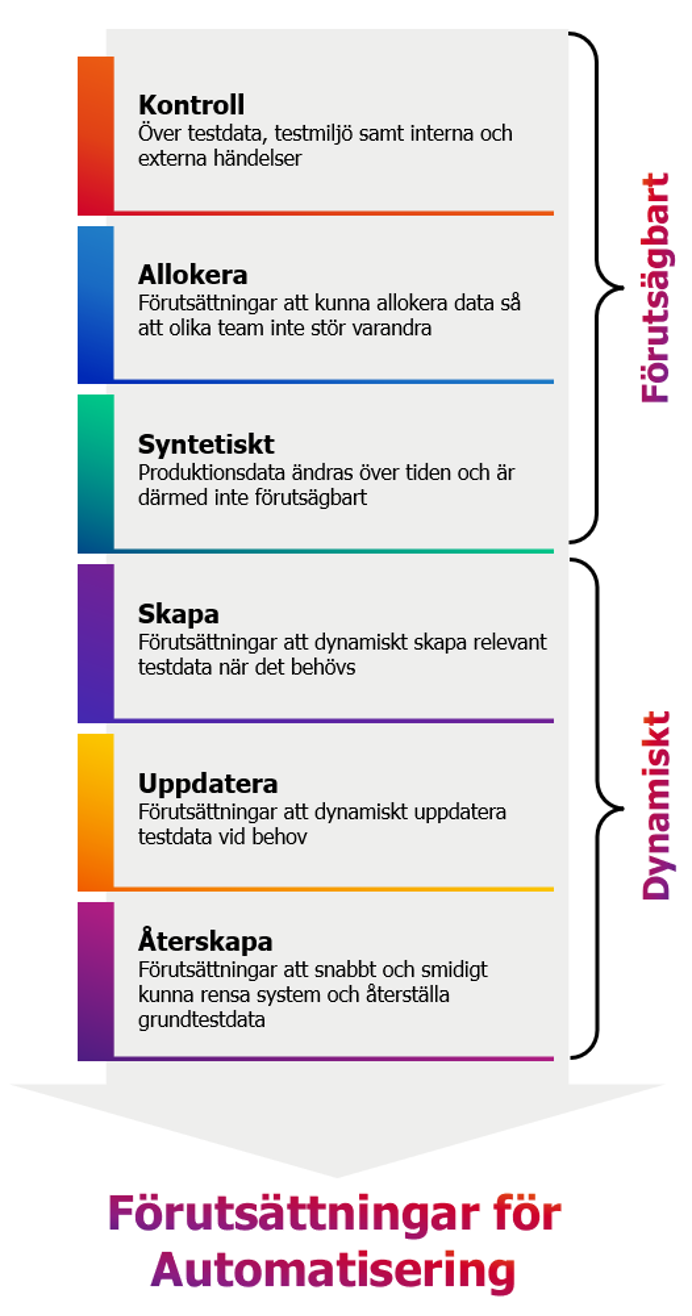
Förutsägbart data
Förutsägbarhet är en nyckelförutsättning. I varje situation och vid varje tillfälle måste vi veta vilket data som finns, vilka värden som är satta och vilket status det har. För att skapa förutsägbarhet har vi definierat ett antal grundförutsättningar.
- I de flesta fall är produktionsdata tidsberoende, det ändras över tiden, därmed behöver göra en omladdning med jämna mellanrum och då tappar vi både kontroll och förutsägbarhet. Genom att använda syntetiskt data skapar vi ägandeskap och genom ägandeskap skapar vi kontroll. Undantag kan exempelvis vara konfigurationsfiler för switchar, routrar, DNS eller lastbalanserare som inte dynamiskt ändras över tid i produktion, därmed är det statiskt till nästa uppdatering och produktionsdatat kan då vara mycket lämpligt att använda för testautomatisering. Men i de flesta fall är produktionsdata raka motsatsen till lämpligt testdata.
- För att skapa förutsägbarhet måste vi ha kontroll över testdata i sig, vi inte kan ligga i händerna på externa parter. Om vi inte har kontroll över externa system, och aktuellt testdata i dessa, måste vi simulera systemen.
- Vi behöver även skapa kontroll över händelser. Användarbaserade händelser kan hanteras genom testverktyg, antingen som förberedelse eller i form av kontinuerlig lastgenerering.
- Bakgrundsarbeten som synkning med andra system, filöverföringar, periodiska arbeten sker i produktion vid specifika tillfällen för skäl som ofta inte är valida i testmiljöer. Ett importarbete kan exempelvis behöva köras på natten i produktion för att lasten är lägre då, men i testmiljön kan vi bestämma att jobbet körs vid den eller de tidpunkter som passar oss. Likaså det data som importeras måste vi ta kontroll över, inte bara tidsmässigt utan även innehållsmässigt. Om vi inte vet varför vårt data ser ut som det gör, så har vi inte kontroll.
- Om alla använder samma testdata kommer vi att störa varandra och det enda förutsägbara i det fallet är att inget är förutsägbart. Det är alltså av största vikt att vi kan allokera delar av testdatat för specifika syften.
Dynamiskt data
Vårt testdata behöver också vara dynamiskt. Om vi accepterar en agil utvecklingsprocess måste vi också acceptera att vi behöver dynamiskt testdata. Medan vi utvecklar kan kraven justeras eller ändras i grund vartefter vi förstår det grundläggande behovet bättre. Vårt testdata måste följa samma process vilket även är ett av skälen till att vi inte ska använda produktionsdata: Det vi utvecklar ligger ofta utanför ramen för existerande funktionalitet och då gör rimligen produktionsdata det med.
För att testningen inte ska bli en flaskhals behöver vi därför kunna skapa testdata vid behov och det kräver ofta någon form av systemstöd. Det här är nyckeln till effektiv testning (automatiserad och manuell), rätt data vid rätt tillfälle.
Slutligen finns det ofta behov av att rensa en testmiljö. Det kan gälla att kopiera ner produktionsmiljön för att garantera att mjukvara och konfiguration är identiskt, eller det kan vara att ett system kraschat och inte kan återställas. Om vi ändå har systemstöd för att skapa testdata och vi dessutom dokumenterar vårt data för att kunna allokera, då är steget till att kunna återställa testdata ofta litet.
Sammanfattning
Testautomatisering har ibland en nästan magisk aura, får vi bara till automatisering så är allt löst och sötebrödsdagar väntar. Men att exekvera tester bara för att man kan leder ofta till förlorad tid när man får felindikationer som beror på omständigheter och inte systemet i sig, kanske att en process tagits ner för att laddas om.
Det behövs en strategi, helst en bolagsöverskridande strategi. Den behöver inte gå in på detaljer, men den ska lägga grunden för transparens mellan utvecklingsteamen och helst även kadens (det vill säga att leveranser från olika team görs synkroniserat).
Sist men inte minst behövs testdata som är dynamiskt och förutsägbart, det vill säga testdata som vi har full kontroll över, och i de flesta fall innebär det att produktionsdata inte kvalificerar.
Får man till det här blir inte bara testprocessen mer effektiv, det öppnas dessutom många nya möjligheter. Om en switch, lastbalanserare eller proxy uppdateras finns som regel inga direkta tester, men ett snabbt regressionstest av de ingående systemen avslöjar snart eventuella fel. Rent mervärde!

Inläggsförfattare
Terminologi och referenser
[1] GDPR
General Data Protection Regulation
På svenska: Dataskyddsförordningen (DSF)
[2] Anonymisering
Att ändra på information så att den inte går att härleda till en enskild individ. En envägsprocess, det vill säga att det inte går att vända processen för att identifiera individen
[3] Pseudonymisering
Att ändra på information så att den oinvigde inte kan härleda till en enskild individ. Den som besitter rätt information kan vända processen och identifiera individen. Syftet är att informationen ska vara anonym för det flertal som bearbetar informationen men inte behöver veta vem det berör, men att utvalda individer ska kunna identifiera individen vid behov
[4] Syntetisering
Att skapa data som inte har någon koppling till verkligt data och därmed inte kan härledas till någon individ eller organisation
[5] Luhn-algoritm
En matematisk algoritm som används för att validera rimlighet av exempelvis personnummer eller kontonummer. I exempelvis personnummer är den sista siffran beräknad med Luhn-algoritm och benämns kontrollsiffra. Algoritmen är inte till för att bekräfta att personnumret är korrekt, det syftar bara till att upptäcka de mest uppenbara felskrivningarna
[6] Verifikation
I testsammanhang definieras test som att leta efter fel eller potentiella fel. Verifikation däremot förutsätter att test redan utförts och syftar till att verifiera att funktionaliteten som tidigare testats inte har försämrats. Ett typexempel är att testa funktionaliteten, men efter att ett nytt uppgraderingsförfarande använts, verifierar man att funktionaliteten fortfarande är intakt för att säkerställa att processen fungerat.
[7] Mitigera
Att mildra eller lindra skärpan eller intensiteten av något. Se Svenska akademins ordbok (www.saob.se)



