
Anonymiserat produktionsdata - Myt eller ren fiktion: del 4
Del 4: Söndra och härska
Klassisk hantering av datamodeller och projekt, dela upp så blir det lättare att hantera. Det gäller även testmiljöer och för att bli riktigt effektiva i utveckling och test måste vi ha rätt miljöer för rätt testning. Det går så klart inte att hitta en lösning som gäller för alla situationer, men här vill jag gå igenom ett generellt koncept som stödjer både funktionell testning med fiktivt data, integrationstest och E2E test/acceptanstest.

Som konsult möter jag i princip dagligen kunder som har problem med testdata och kunder som vill få i gång testautomatisering, men som inte lyckas. I de flesta fallen handlar det om att kunden vill använda produktionsdata som testdata, ibland med anonymisering för att säkerställa att man följer GDPR.
Med den här artikeln vill jag slå hål på myter kring att produktionsdata är lämpligt testdata och att personuppgifter blir lagligt testdata om man bara anonymiserar. Artikeln är indelad i 5 avsnitt enligt bilden och det här är så klart den fjärde delen som handlar om testmiljöer.
Externa integrationer orsakar lätt problem testdatamässigt, vi har normalt ingen kontroll över vare sig data eller händelser i externa system. Att identifiera testdata som matchar mellan olika externa system är också svårt, jag kanske kan hitta samma registreringsskylt i två olika system, men de syftar antagligen till olika bilmärken och ägare.
Problemet här ligger ofta i att försöka sig på för många olika sorters test i en och samma miljö. Det finns en övertro att om jag utför extensiva End-to-end (E2E) tester i en fullt integrerad testmiljö så behöver jag inte utföra så mycket funktionella tester eller integrationstester, och då blir jag effektiv.
Att separera testmiljöer för funktionstest från integrationstest och E2E test är ofta effektivt och ju större och mer komplexa de interna lösningarna är desto mer förtjänst.
Genom att ersätta externa tjänster med simulerade system kan vi få kontroll över testdata och framför allt händelser, därmed kan vi öka effektiviteten. Som bieffekt minimerar vi risken att påverka någon eller något externt. Det vill säga, om jag testar processer kring dödsfall, så riskerar jag inte att en extern integration resulterar i att en riktig person blir dödförklarad. Det sistnämnda kan låta orimligt, nästan löjeväckande, men varför har det i så fall hänt? Och om det händer, vad blir kostnaden i form av GDPR sanktioner eller dålig publicitet?
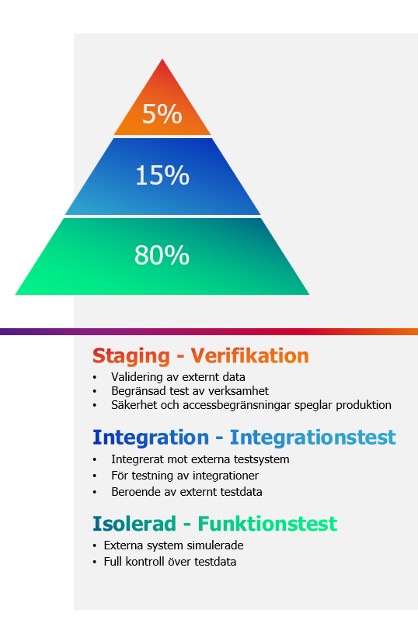
I bilden bredvid har jag definierat 3 testmiljöer med olika syften.
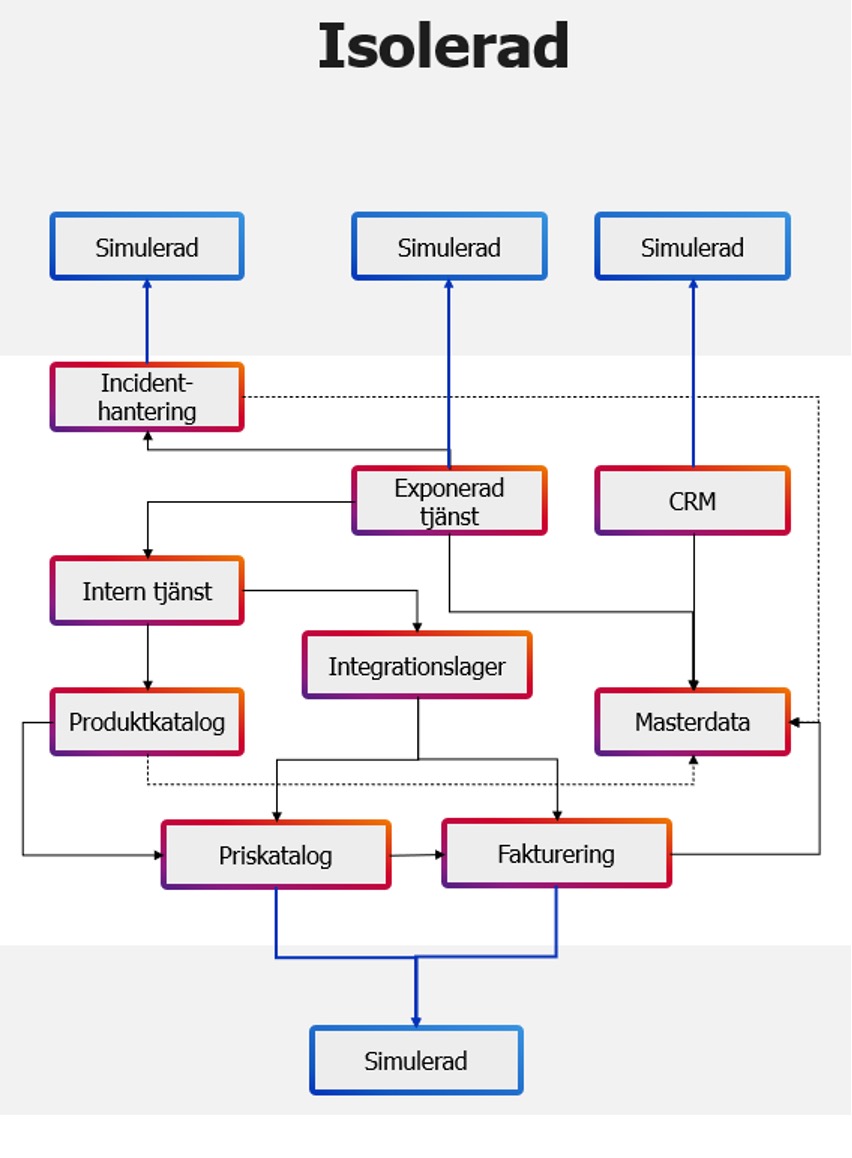
Isolerad
Utgör grunden, här är allt data syntetiskt och alla externa integrationer är simulerade. Det ger oss full kontroll över data och händelser och vi kan dynamiskt skapa nytt data vid behov. Observera att interna integrationer inte simuleras, för här ska vi ha kontroll över data och händelser. Här görs majoriteten av testningen, här gissningsestimerat till 80%.
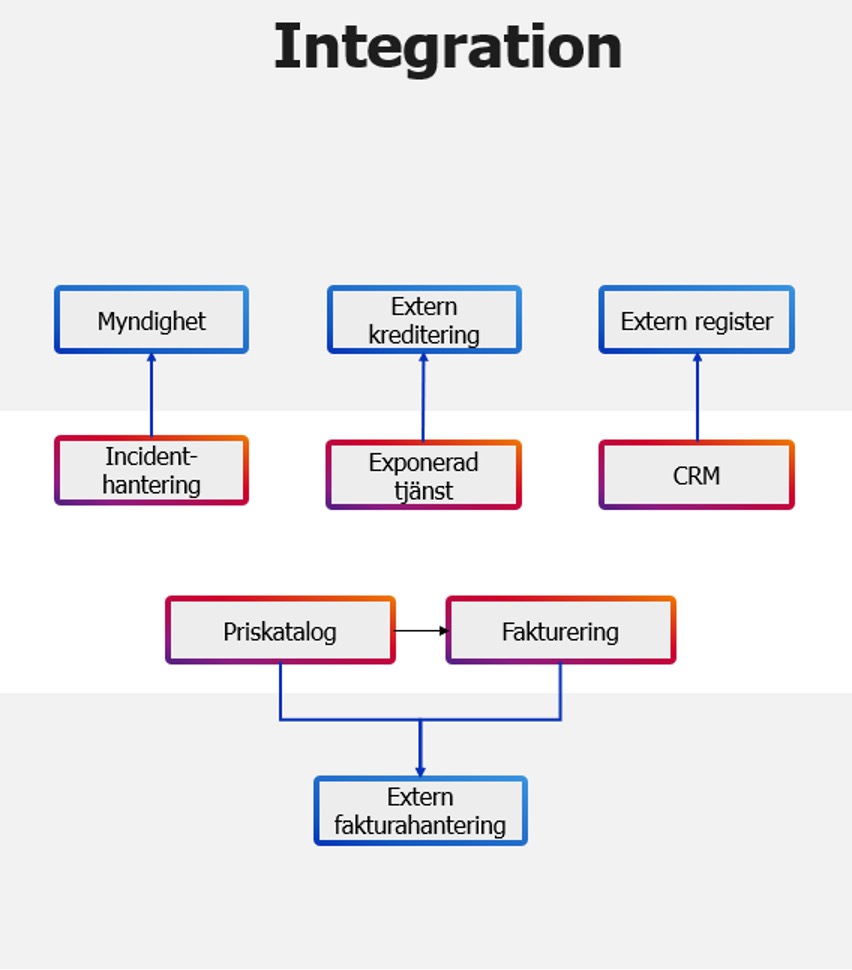
Integrationsmiljö
I den här miljön testas externa integrationer för att kunna bygga simulatorer. Det här är grundbulten till att kunna testa i Isolerad miljö och måste ske oavhängt projekten, eftersom simulatorer måste underhållas oavsett vilka projekt som är aktiva.
Simulatorerna behöver inte var perfekta från början, det är bättre att börja med statiska svar och sedan expandera i små steg baserat på prioriterat behov.
I början kan man förvänta sig att simulatorerna har brister, men det löses på samma sätt som vilka buggar som helst.
Därefter testas integrationerna kontinuerligt för att upptäcka ändringar eller uppdateringar, det sistnämnda görs gärna automatiserat genom exempelvis script.
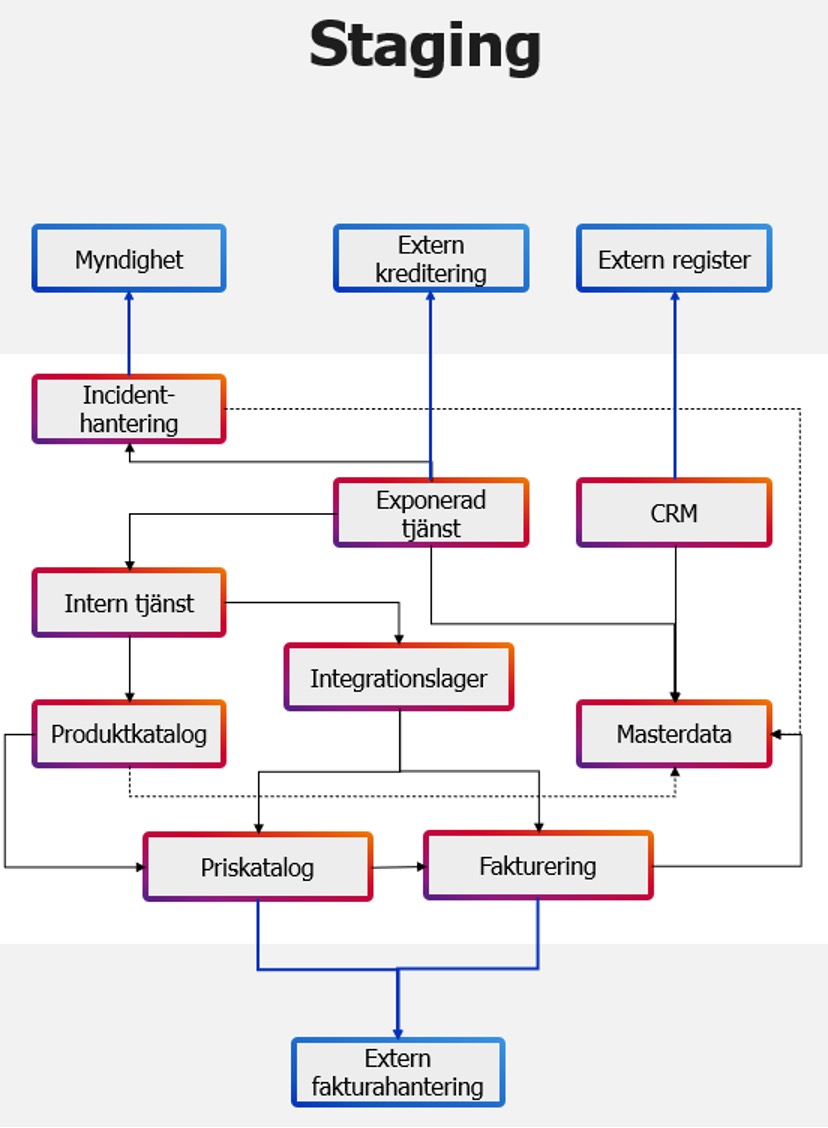
Staging
Den här miljön är egentligen inte till för testning, den är till för att verifiera data och processer, det är en liten men viktig skillnad. Testning utförs för att hitta fel och höja kvalitén, verifiering sker först efter testning och med syftet att bekräfta att testad funktionalitet inte förstörs vid exempelvis miljöskifte. Typiska exempel är:
- Uppgraderingsförfarande, varje delsteg är testat i förväg, men inte helheten
- End-2-end test. Testning av (komplexa) dataflöden genom flera system, eller att följa data genom dess livscykel
I regel fungerar fiktivt data bäst även här, men med de externa integrationerna tappar man kontrollen över data och behöver vanligen anpassa sitt testdata efter det som finns i de externa systemen. Det här gör testautomatisering svårt och även manuella testprocesser blir mindre effektiva, även felsökning blir mer komplext och mindre effektivt, därför bör så mycket som möjligt av testningen skjutas över till den isolerade testmiljön eller integrationsmiljön.
De exakta värdena kan förstås diskuteras och mitt värde på 5% är en ren gissning, men poängen består: Bara en mycket liten del av test/verifikation göras här.
Sammanfattning
I många av de bolag jag arbetat med finns flera testmiljöer: testmiljö, integrationsmiljö, E2E-miljö, acceptanstestmiljö, UAT-miljö eller stagingmiljö, men ofta saknas tydliga syften med de olika miljöerna. Att bara ha fullt integrerade miljöer ger bra förutsättning för test, men är ineffektivt. Att flytta över majoriteten av testningen till en ”Isolerad” miljö, utan externa integrationer kan i min åsikt höja effektiviteten och samtidigt minska riskerna.
Nyckeln ligger i att ha en övergripande teststrategi med ett tydligt syfte för respektive miljö, utan att för den delen detaljstyra hur testning ska skötas.

Inläggsförfattare
Terminologi och referenser
[1] GDPR
General Data Protection Regulation
På svenska: Dataskyddsförordningen (DSF)
[2] Anonymisering
Att ändra på information så att den inte går att härleda till en enskild individ. En envägsprocess, det vill säga att det inte går att vända processen för att identifiera individen
[3] Pseudonymisering
Att ändra på information så att den oinvigde inte kan härleda till en enskild individ. Den som besitter rätt information kan vända processen och identifiera individen. Syftet är att informationen ska vara anonym för det flertal som bearbetar informationen men inte behöver veta vem det berör, men att utvalda individer ska kunna identifiera individen vid behov
[4] Syntetisering
Att skapa data som inte har någon koppling till verkligt data och därmed inte kan härledas till någon individ eller organisation
[5] Luhn-algoritm
En matematisk algoritm som används för att validera rimlighet av exempelvis personnummer eller kontonummer. I exempelvis personnummer är den sista siffran beräknad med Luhn-algoritm och benämns kontrollsiffra. Algoritmen är inte till för att bekräfta att personnumret är korrekt, det syftar bara till att upptäcka de mest uppenbara felskrivningarna
[6] Verifikation
I testsammanhang definieras test som att leta efter fel eller potentiella fel. Verifikation däremot förutsätter att test redan utförts och syftar till att verifiera att funktionaliteten som tidigare testats inte har försämrats. Ett typexempel är att testa funktionaliteten, men efter att ett nytt uppgraderingsförfarande använts, verifierar man att funktionaliteten fortfarande är intakt för att säkerställa att processen fungerat.
[7] Mitigera
Att mildra eller lindra skärpan eller intensiteten av något.
Se Svenska akademins ordbok (www.saob.se)



